Process Element
借助 oas 的 assets 工具,你可以非常方便快捷的创建修改管理 过程元素。
我们考虑这样的情形:在某个固定的坐标下需要识别每一个图片,或者是在某个范围下识别图片,手动输入坐标是一件极其低效的操作,又如何快速的截取所匹配的图片,如何高效稳定的配置这些脚本运行过程中所需要的参数(如图片识别的阈值,识别之后点击的区域,图片的名字等等)。难道说仅仅只是针对图片的吗,ASSETS 工具应该对这类高度同具体的游戏任务相关的实现简便高效的配置,以提高信息的高效使用以及代码的复用。
下面将详细介绍其具体的使用,但是再此之前我们还需要探讨如何这类Process Element信息的存储问题,首先很自然的希望将其保存为json格式的数据运行时读取,而Alas 将其extracte生成代码。在 oas 里将两者结合,使用 RULE 生成全部的json信息后,extracte生成一个资源类,将其继承即可快速访问assets。
RULE Tool
在正式介绍使用之前先介绍我们的规则工具,首先修改 ./module/config/argument/setting.json 的 branch 为 dev, 这将使你的 oas 变成开发版。启动根目录下的 gui.py 这个是老版本的oas。
在保证实例成功启动后
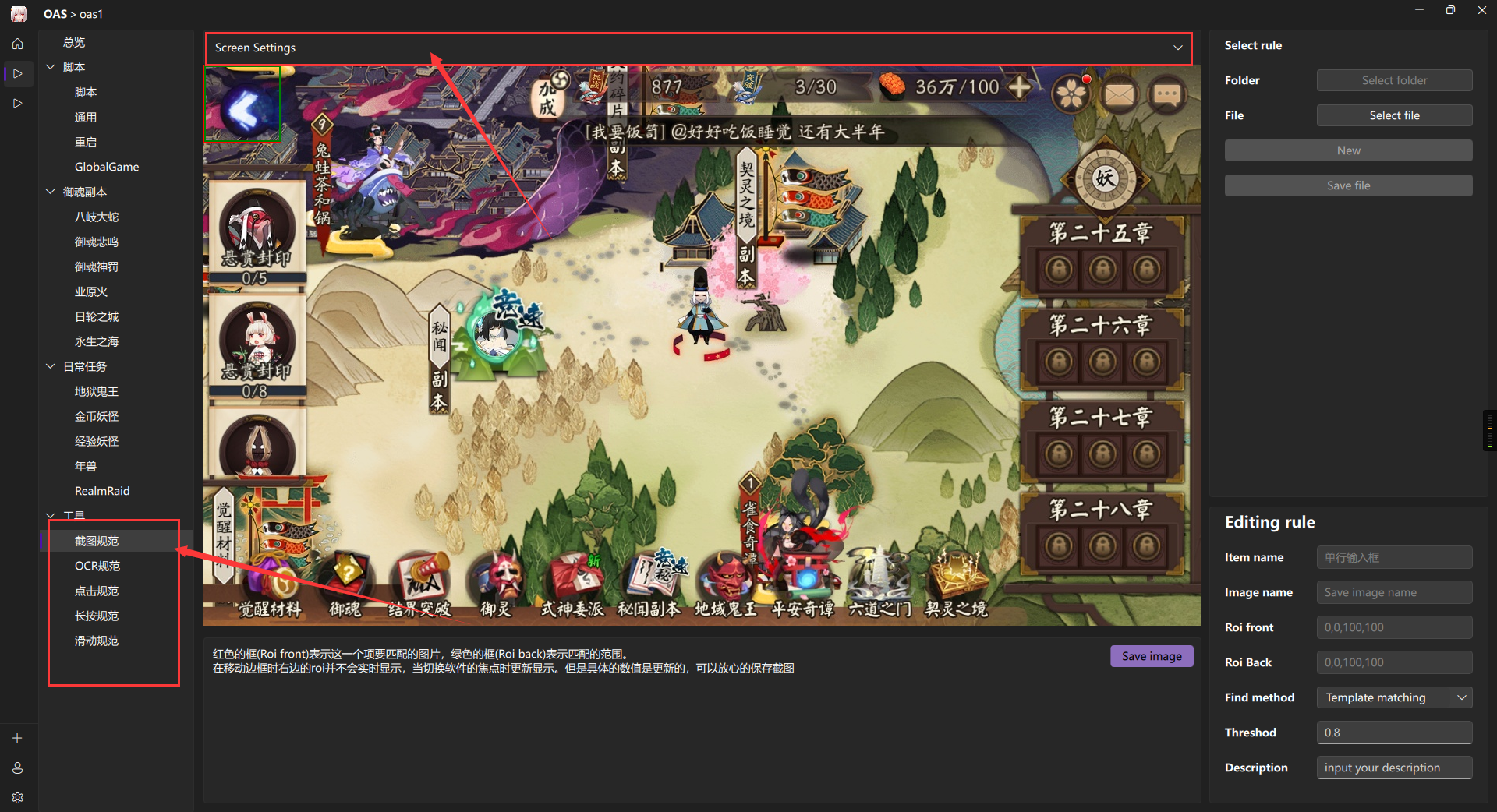
如果不出意外 oas 会将 模拟器截屏投屏到 界面上
写的时候图快,就没认真当投屏来写。轻点喷
点击最上方的Screen Setting 即可出现投屏的设置
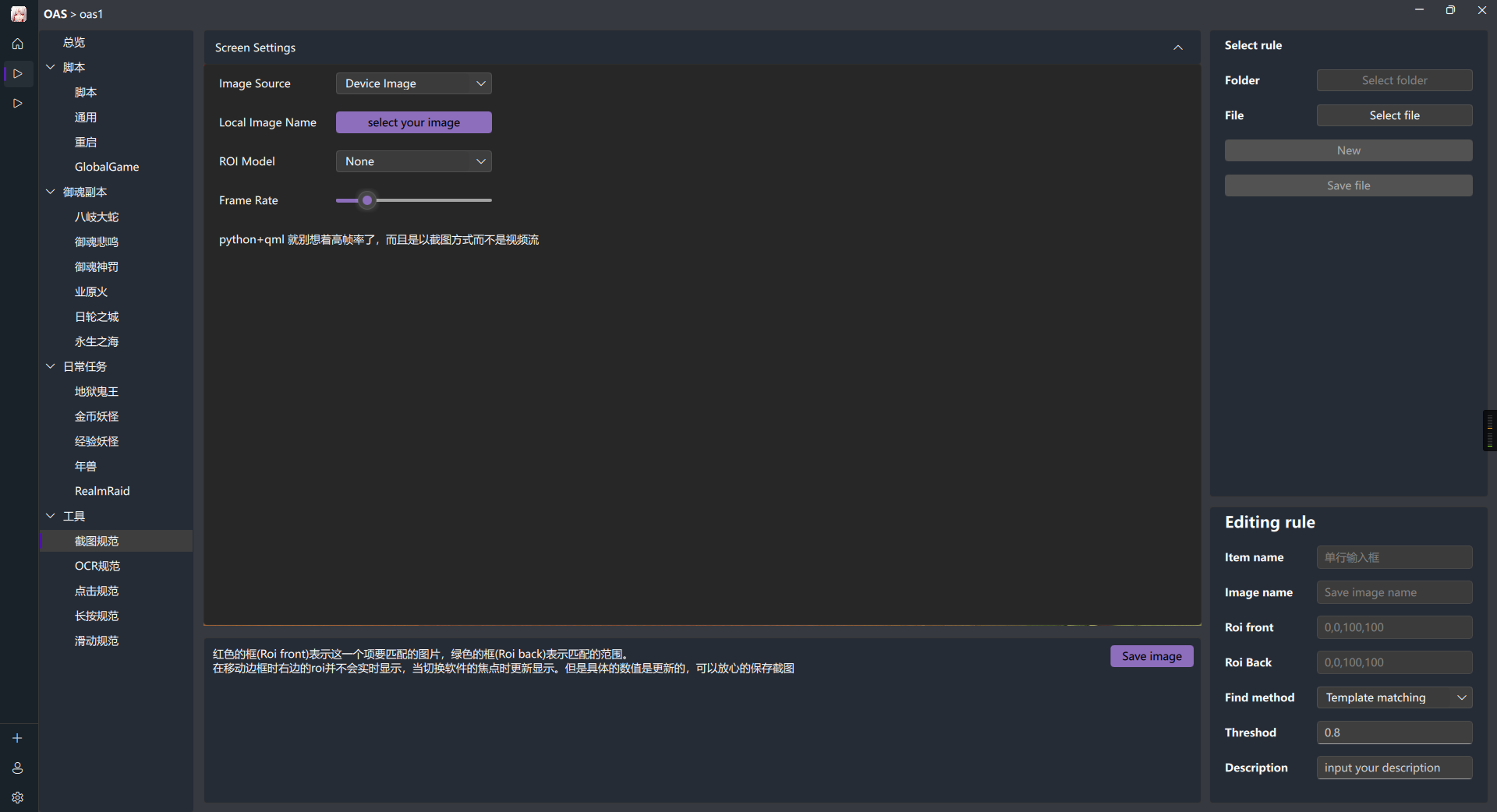
Image Source: 截屏源,可选来自模拟器还是来自本地图片
Local Image Name: 本地图片的路径
Frame Rate: 帧率默认两帧
ROI Model: 两个框的布尔模式默认None, 第二种为Same两个框重叠保持位置大小一致,第三种为包含即前框必须在绿框内。
- 红框/前景框/默认框/ROI_Front: 这个是我们后面所使用的默认的一个ROI
- 绿框/背景框/备选框/ROI_Back: 备选的框,是否被使用取决于具体的RULE
danger无论什么的时候请不要手贱乱拖动边框,保持一个良好的习惯
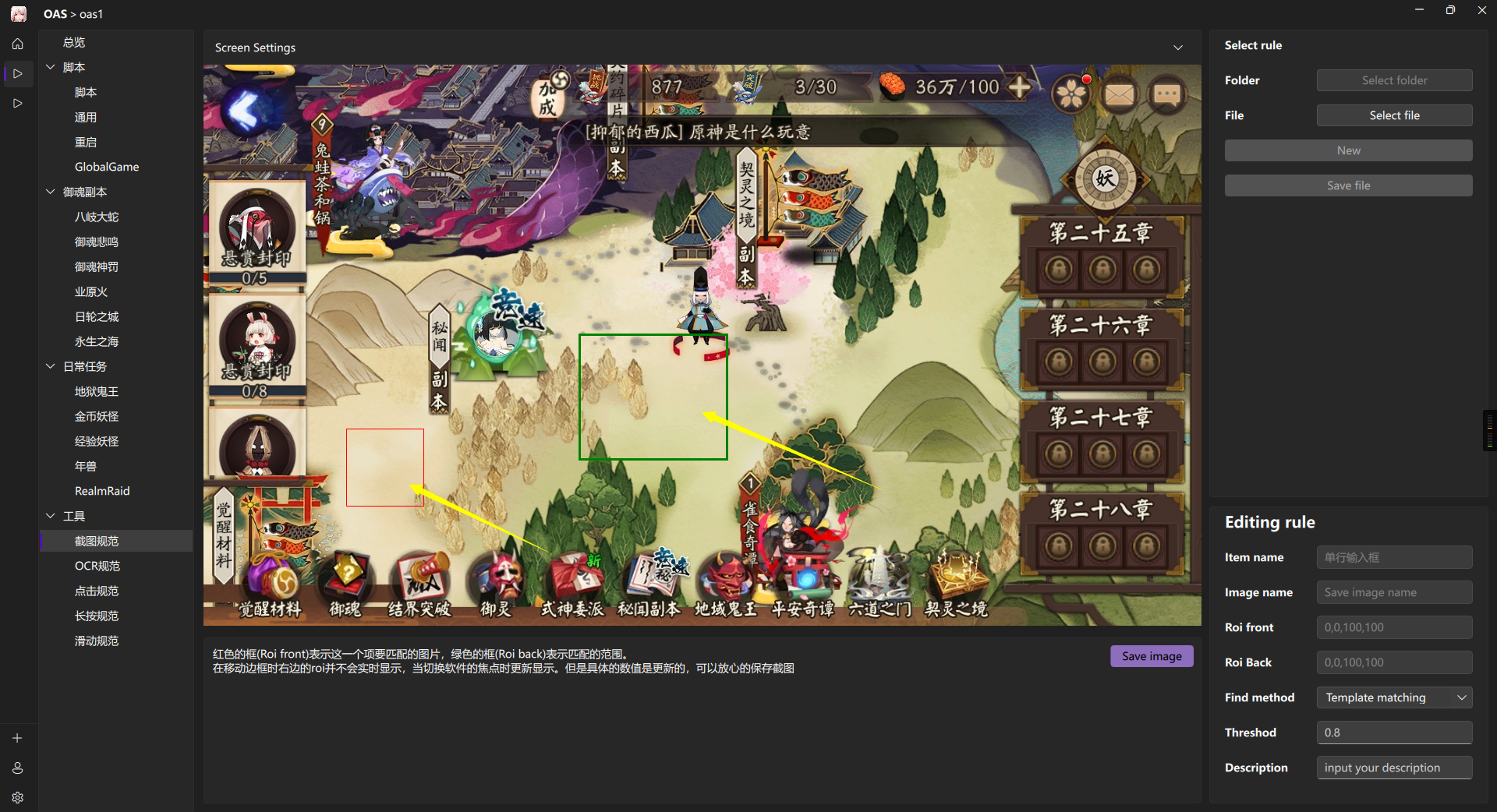
Rule
每一种不同的Rule工具都需要单独新建一个json文件,同一种类型的Rule可以有多份json文件 我们鼓励使用多份json文件而不是一直往一个json文件加信息
Image
绿框表示要识别的图片区域
红框表示要截图的目标图片
新建空的
image.json文件,路径一般是./tasks/<任务名>/res/。image.json和res这两个并不是必须的一致这只是约定成俗的。在 oas 的
RULE Tool打开建立的文件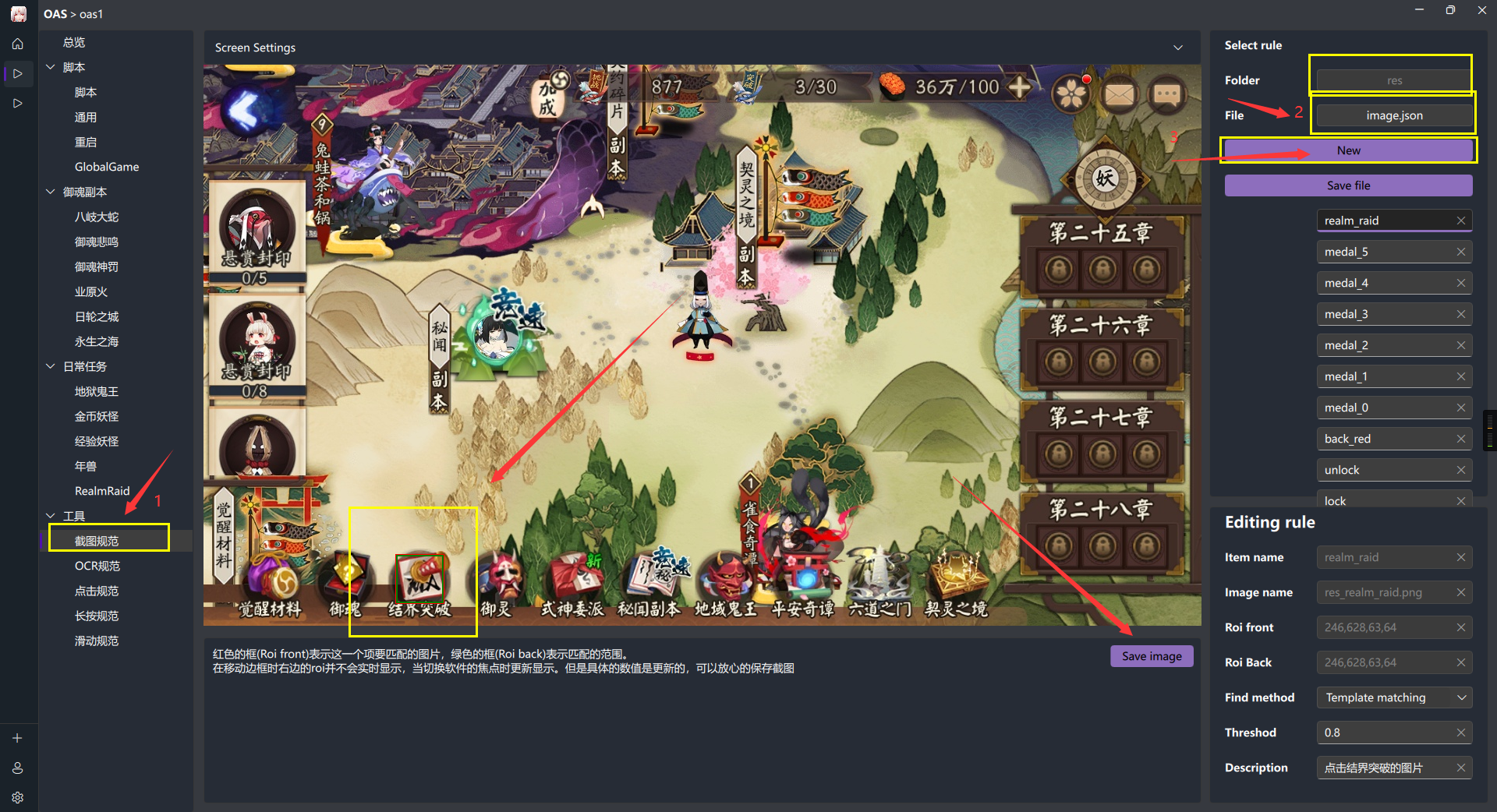
一般打开一个新的右侧列表为空,我们点击
New新建一项,修改名字回车,此时发现右下方Item name和Image name也是同步修改(这意味着我们无需手动管理其命名)tipitme name 仅仅支持 小写字母 + 下划线
配置ROI:这一步非常重要,首先你先确定你所要识别的图片是否会移动,这决定了识别的速率。
- 如果是固定的图片: 你需要将
Screen Setting的ROI Model切换至Same模式,这个时候我们就可以一起拖动两个框了,你需要将两个框拖动到要识别的图片位置 - 如果是非固定的图片:你需要将
Screen Setting的ROI Model切换至Include模式,或者是None模式,移动绿框为其可能出现的区域而移动红框到当前目标图片的区域
- 如果是固定的图片: 你需要将
保存目标图片, 点击
Save image即可保存图片。一定不要忘记了保存图片修改其他辅助信息:
Threshod表示图片匹配的阈值保存默认即可(因为你还可以在代码中手动设置匹配阈值),Description为描述这一项的代码注释,最后会被提取为注释重复步骤3、4、5、6直到所有的目标图片记录
最后点击右边的
Save File保存文件,但是建议每隔几个保存一次
Click
红框表示默认的点击区域
绿框表示备用的点击区域(一般用不到)
操作流程同Image一致
LongClick
红框表示默认的点击区域
绿框表示备用的点击区域(一般用不到)
操作流程同Image一致
Duration这个参数表示长按的时间,单位ms
Swipe
红框表示滑动的起始区域
绿框表示滑动的终止区域
操作流程同Image一致
Mode这个参数表示滑动的模式,是模拟人手滑动(赛贝尔曲线)还是直线
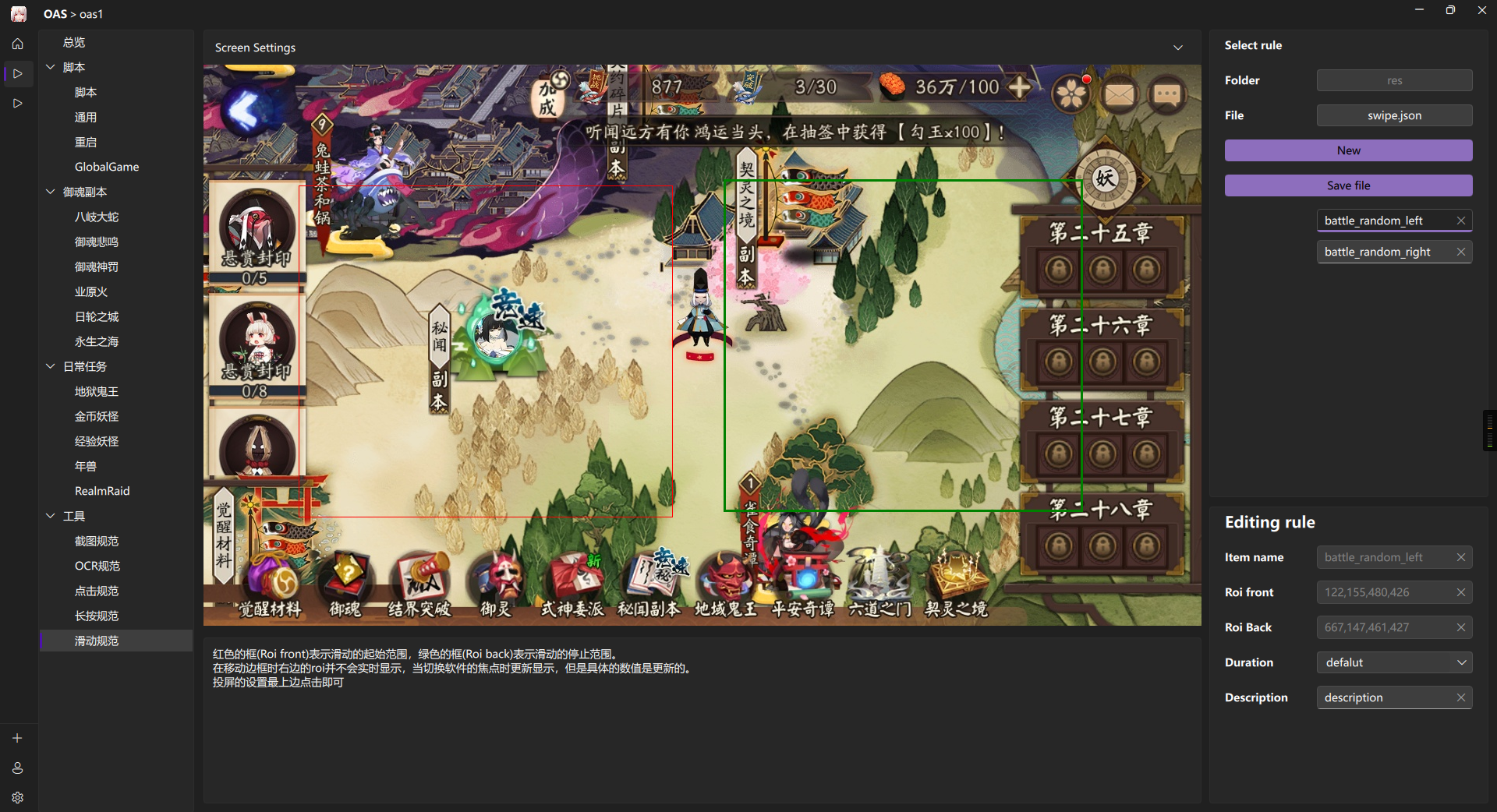
Ocr
红框表示Ocr的范围
在介绍使用之前我们先针对 OCR 的使用场景进行分析:
- Single:有一块固定的ROI,我能保证里面只有一项字符,无论文字的方向是横的还是竖的
- Full: 有一块相对比较大的ROI,文字的可行的位置不固定,可能会有很多项字符,甚至方向也不确定
- Digit: 有一块固定的ROI,能保证这一项是数字
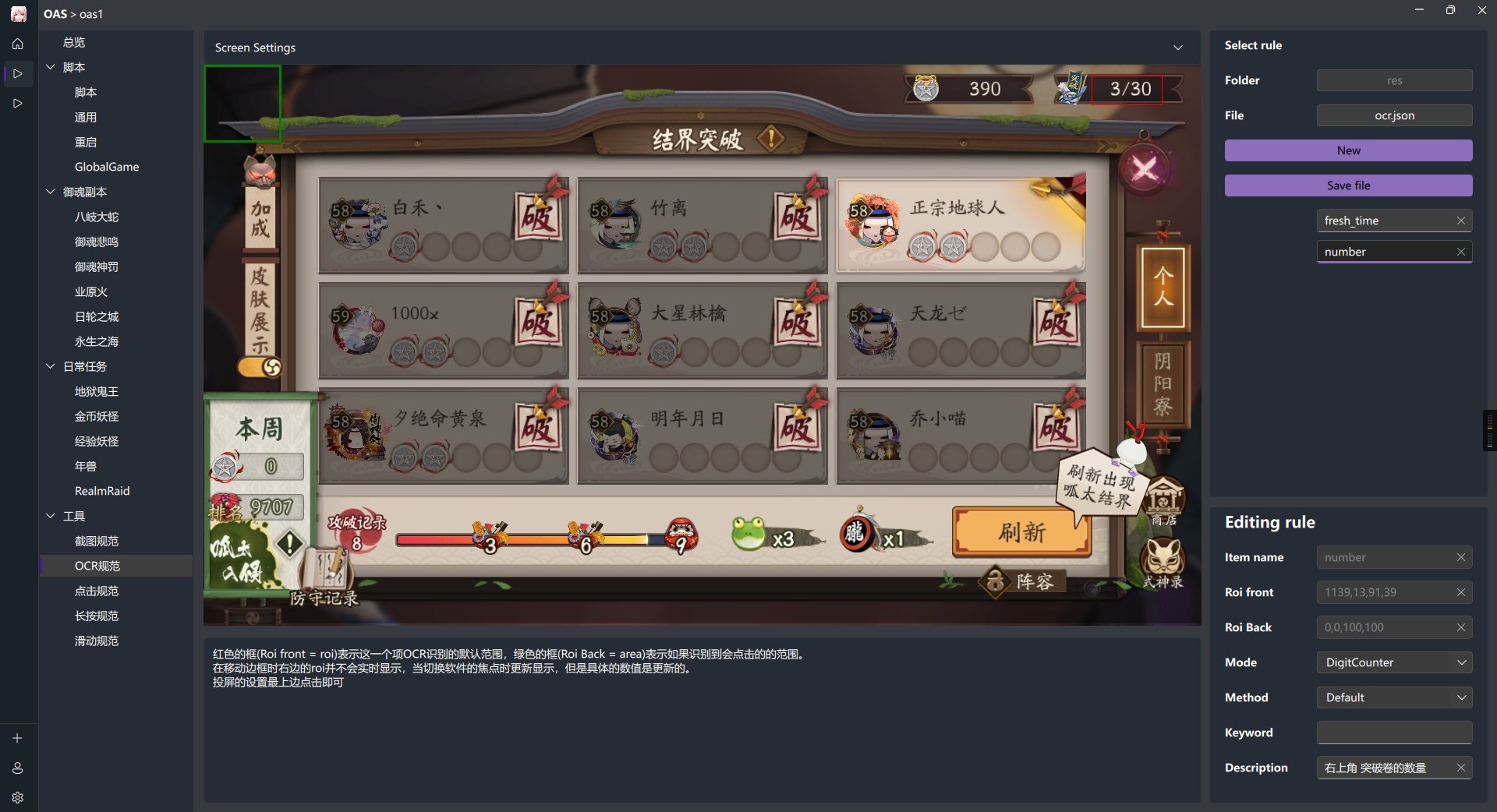
- DigitCounter:有一块固定的ROI,需要获取计数值,如上图的
3/30 - Duration:有一块固定的ROI, 需要获取时间
01:30:00
操作流程同Image一致
- Mode: 根据使用场景进行选择
- Mothod: Default
- Keyword:如果Mode是Single或者是Full表示要匹配的字符,如果是其他的就不填
List
红框表示每一项的范围
绿框表示整个列表的范围
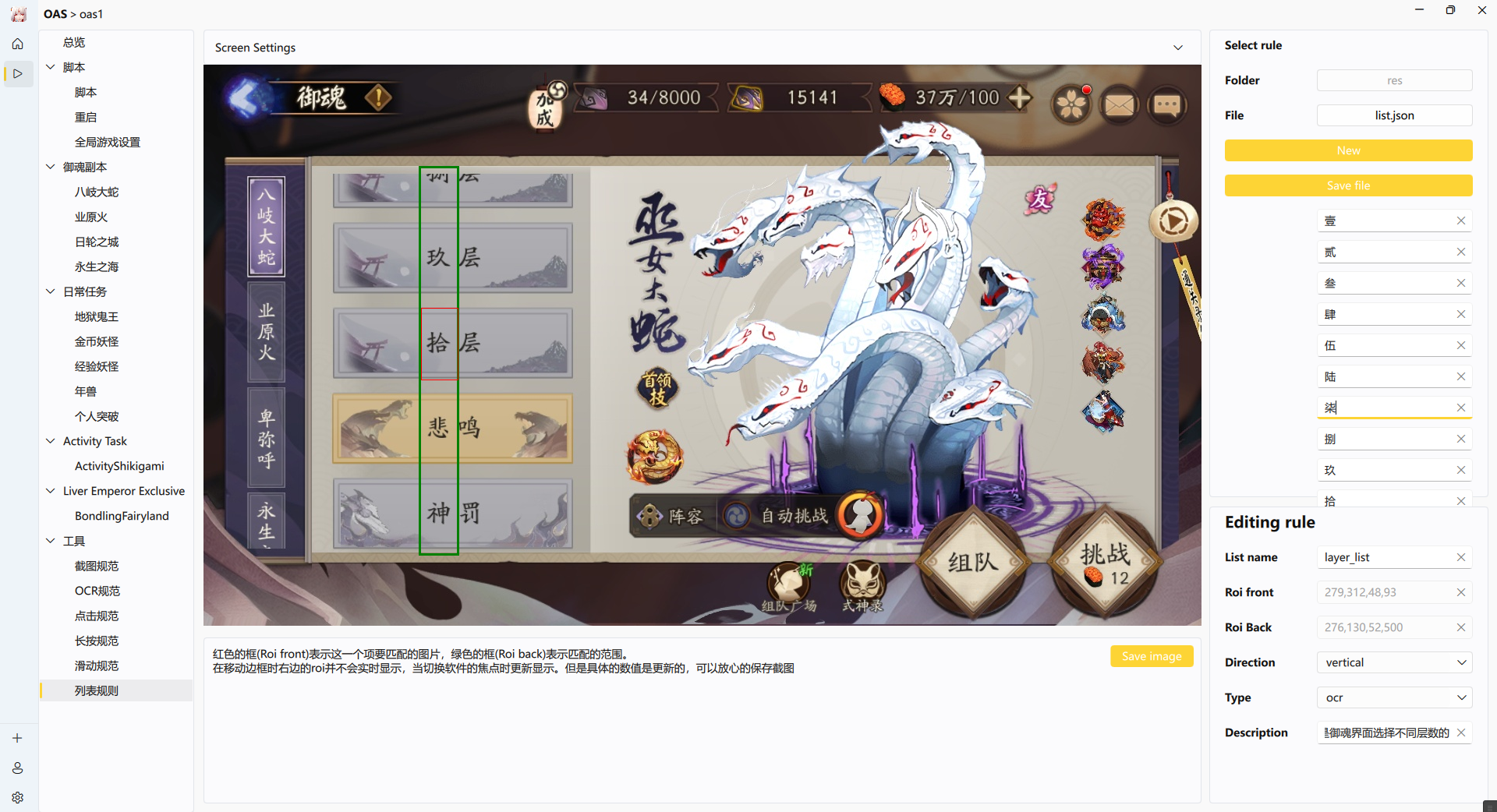
RuleList的应用场景是为了支持游戏界面中无法一次性展示所有元素的界面操作,但是这并不可以满足所有的滑动列表。
其底层的接口还是RuleImage 或者是 RuleOcr,还是存在相对的局限性。
如果是基于Ocr来操作,请将Type选为ocr
为此绿框就是ocr识别所有文字的的区域,不同于其他的Rule工具,RuleList的每一项就是具体游戏的元素,你需要同游戏的顺序一致定义每一项的值,上图中定义了御魂的层数
为此将方向选中为竖直vertical。
有一项非常重要:每一个元素的大小要符合实际的大小,上图中红框的高度同游戏界面中的高度一致,这是为了便于计算每次滑动的距离
基于ocr非常大的局限性是,你需要保证游戏界面中仅仅出现你所定义的这些字符
如果是基于Image来操作,将Type选为image
需要多注意的一点是你需要为每一种元素进行截图保存
!!!绝大多数场景下建议使用ocr类型的
Assets
在生成了所有的json数据后,你需要使用./module/dev_tools/assets_extract.py来将信息提取成Assets
直接运行assets_extract.py即可,生成./tasks/<任务名>/assets.py文件
from module.atom.image import RuleImage
from module.atom.click import RuleClick
from module.atom.long_click import RuleLongClick
from module.atom.swipe import RuleSwipe
from module.atom.ocr import RuleOcr
# This file was automatically generated by module/dev_tools/assets_extract.py.
# Don't modify it manually.
class RealmRaidAssets:
# Image Rule Assets
# 点击结界突破的图片
I_REALM_RAID = RuleImage(roi_front=(246,628,63,64), roi_back=(246,628,63,64), threshold=0.8, method="Template matching", file="./tasks/RealmRaid/res/res_realm_raid.png")
# Ocr Rule Assets
# 刷新的时间
O_FRESH_TIME = RuleOcr(roi=(1042,582,85,36), area=(0,0,100,100), mode="Duration", method="Default", keyword="", name="fresh_time")
# 右上角 突破卷的数量
O_NUMBER = RuleOcr(roi=(1139,13,91,39), area=(0,0,100,100), mode="DigitCounter", method="Default", keyword="", name="number")
至此你可以使用这个提取的类来快速的访问 过程元素
API
没有特殊说明这些类都是位于./module/atom/文件夹下,这些类是由前面所使用Assets生成的你大可不必在意如何初始化
RuleImage
RuleImage.match(self, image: np.array, threshold: float = None) -> bool:
输入一张截屏(1280x720)根据初始化信息判断是否出现
RuleImage.coord(self) -> tuple:
返回默认的ROI(红色框的随机坐标)如 100, 150
RuleImage.coord_more(self) -> tuple:
返回备选的ROI(绿色框的随机坐标)如 100, 150
RuleClick
- coord(self) -> tuple: 同RuleImage.coord
- coored_more(self) -> tuple: 同RuleImage.coord_more
- center(self) -> tuple: 返回roi_front的中心坐标
- move(self, x: int, y: int) -> None: 移动roi_front
RuleLongClick
- 继承于RuleClick
RuleSwipe
- coord(self) -> tuple: 从roi_front随机获取坐标 和从roi_back随机获取的坐标 类似:x1, y1 x2, y2
- trace(self) -> list: 获取滑动的路径,list的每一项都是tuple 类似:[(x1, y1), (x2, y2)]
RuleOcr
coord(self) -> tuple: 这个函数要求在使用ocr方法后使用,返回匹配到的文字的一个随机坐标,同时也是roi的坐标
ocr(self, image, keyword=None): 针对不同的模式执行不同的ocr
match self.mode:
case OcrMode.FULL: return Full.ocr_full(self, image, keyword)
case OcrMode.SINGLE: return Single.ocr_single(self, image)
case OcrMode.DIGIT: return Digit.ocr_digit(self, image)
case OcrMode.DIGITCOUNTER: return DigitCounter.ocr_digit_counter(self, image)
case OcrMode.DURATION: return Duration.ocr_duration(self, image)
case _: return NoneFull-> tuple: 检测整个图片的文本,并对结果进行过滤。返回的是匹配到的keyword的区域。如果没有匹配到返回(0, 0, 0, 0)Single-> str: 返回识别到的字符串Digit-> int : 返回识别到的数字,如果没有则返回0。注意这个是int的不是floatDigitCounter-> tuple: 返回识别到的数字计数,如果没有则返回0, 0, 0Duration-> timedelta: 返回识别到的时间间隔 如果没有则返回timedelta(00:00:00)
RuleList
self.swipe_pos()
获取要滑动的两个点的坐标
number: int=2 # 要滑动的元素个数
after: bool=True # 向前滑动还是向后滑动,水平方向after为右边,竖直方向后after为下边self.image_appear()
判断所定义的图片是否出现
image: np.ndarray # 模拟器的截图
name: str # 图片保存的名字,也就是使用工具输入时候的名称self.ocr_apper()
判断所定义的文字是否出现
image: np.ndarray # 模拟器的截图
name: str # 使用工具输入时候的名字
ImageGrid
表示某一个场景中出现的所有的点击图片
self.__init__()
底层依赖RuleImage
images: list[RuleImage]self.find_anyone()
在这些图片中锁定一张图片,返回的是识别到的图片的对象